Scalable and Performant ASP.NET Core Web APIs: ORM Choice
This is another post in a series of posts on creating performant and scalable web APIs using ASP.NET Core. In this post we’ll start to focus on data access within our API which is the often the cause of performance bottlenecks. We’ll start off with chosing our object relationship mapping framework / library (ORM) …
Be careful with EF Core
Entity Framework Core nicely encapsulates the database details from developers. However this approach does carry some performance overheads and gotchas.
Let’s look at an example. Here’s our database model:
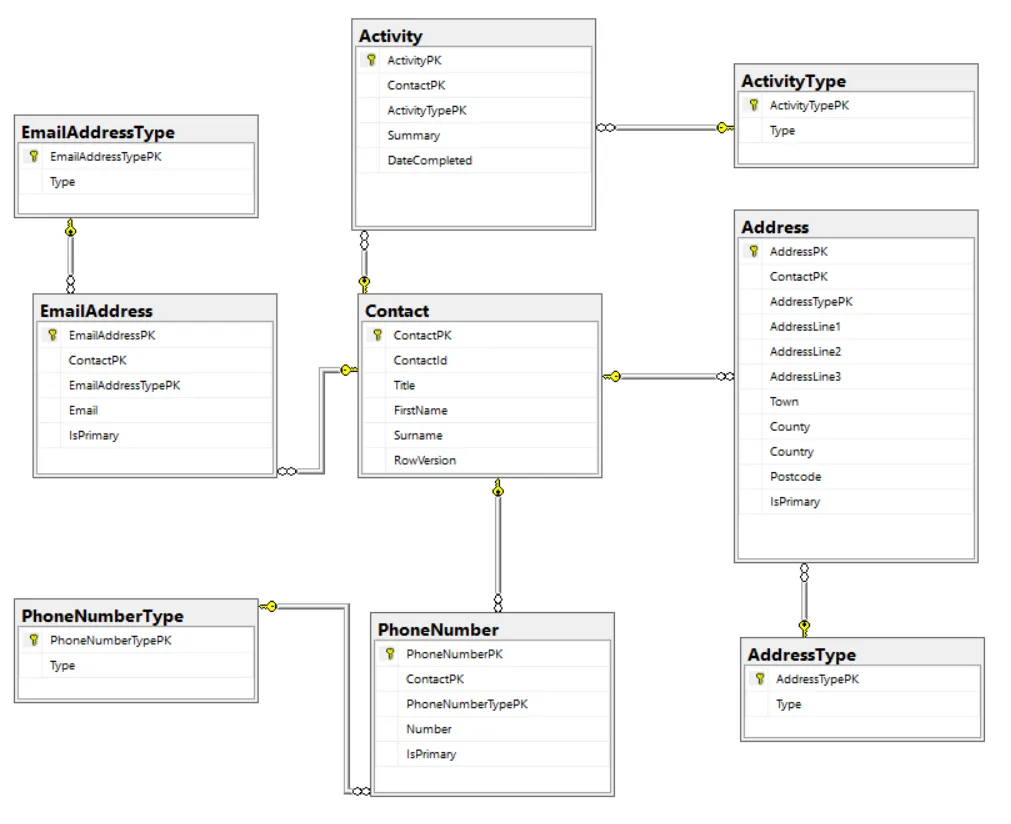
We have a controller action method /contacts/{contactId} that returns a contact record.
[HttpGet("{contactId}", Name = "GetContact")]public IActionResult GetById(Guid contactId){ var contactEntities = dataContext.Contacts.ToList(); var contactEntity = contactEntities .Where(c => c.ContactId == contactId) .SingleOrDefault();
if (contactEntity == null) { return NotFound(); }
return Ok(contactEntity);}Here’s the SQL Profiler trace:

Where’s the WHERE clause!? EF Core has fetched all the data in the Contact table too early because of the .ToList(). If we remove the .ToList(). EF Core behaves a little more as we expect:

Let’s add some more requirements for our action method … We now want to include the primary address, primary email address and primary phone number in /contacts/{contactId}.
The implementation is below. We’ve been good EF Core developers and used .AsNoTracking() so that no unnecessary change tracking occurs. We’ve also been specific about what fields we want to retreive so that EF Core doesn’t fetch more data than we need.
[HttpGet("{contactId}", Name = "GetContact")]public IActionResult GetById(Guid contactId){ var contactEntity = dataContext.Contacts .AsNoTracking() .Include(c => c.Addresses) .ThenInclude(a => a.AddressType) .Include(c => c.EmailAddresses) .ThenInclude(e => e.EmailAddressType) .Include(c => c.PhoneNumbers) .ThenInclude(e => e.PhoneNumberType) .Where(c => c.ContactId == contactId) .Select(c => new DataModel.Contact() { ContactId = c.ContactId, Title = c.Title, FirstName = c.FirstName, Surname = c.Surname, Addresses = c.Addresses.Where(a => a.IsPrimary).ToList(), EmailAddresses = c.EmailAddresses.Where(e => e.IsPrimary).ToList(), PhoneNumbers = c.PhoneNumbers.Where(p => p.IsPrimary).ToList() }) .SingleOrDefault();
if (contactEntity == null) { return NotFound(); }
return Ok(contactEntity);}Here’s the SQL Profiler trace:
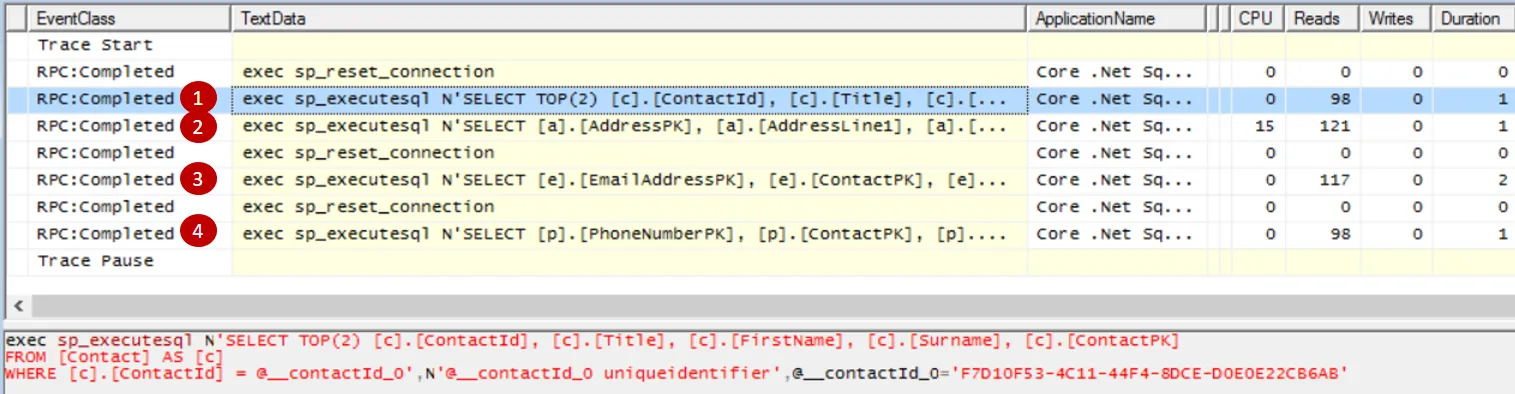
We have 4 calls to the database when a single SQL statement could have done the job.
So, with EF core, we need to know what we are doing and be really careful if we are implementing an API on top of a decent sized database. There are also cases when EF Core is going to generate inefficient SQL or round trip to the database multiple times - that’s just how it works!
Here’s a great post on other performance gothas in Entity Framework. It’s not specifically about EF Core but many of the points do apply.
Dapper helps build performant data access code
Dapper is a micro ORM that doesn’t abstract the SQL from us. In Dapper, we use regular SQL to access the database. Dapper simply maps the data to our c# objects.
Here’s the data access code using Dapper for the example above.
public Contact GetContactById(Guid contactId){ Contact contact = null;
using (IDbConnection connection = new SqlConnection(connectionString)) { connection.Open();
contact = connection.QueryFirstOrDefault<Contact>( @"SELECT ContactId, Title, FirstName, Surname, AddressType.Type AS AddressType, Address.AddressLine1, Address.AddressLine2, Address.AddressLine3, Address.Town, Address.County, Address.Country, Address.Postcode, EmailAddressType.Type AS EmailAddressType, EmailAddress.Email AS EmailAddress, PhoneNumberType.Type As PhoneNumberType, PhoneNumber.Number AS PhoneNumber FROM Contact LEFT JOIN Address ON Contact.ContactPK = Address.ContactPK LEFT JOIN AddressType ON Address.AddressTypePK = AddressType.AddressTypePK LEFT JOIN EmailAddress ON Contact.ContactPK = EmailAddress.ContactPK LEFT JOIN EmailAddressType ON EmailAddress.EmailAddressTypePK = EmailAddressType.EmailAddressTypePK LEFT JOIN PhoneNumber ON Contact.ContactPK = PhoneNumber.ContactPK LEFT JOIN PhoneNumberType ON PhoneNumber.PhoneNumberTypePK = PhoneNumberType.PhoneNumberTypePK WHERE Contact.ContactId = @ContactId AND Address.IsPrimary = 1 AND EmailAddress.IsPrimary = 1 AND PhoneNumber.IsPrimary = 1", new { ContactId = contactId }); }
return contact;}Here’s the SQL Profiler trace confirming only 1 hit on the database: 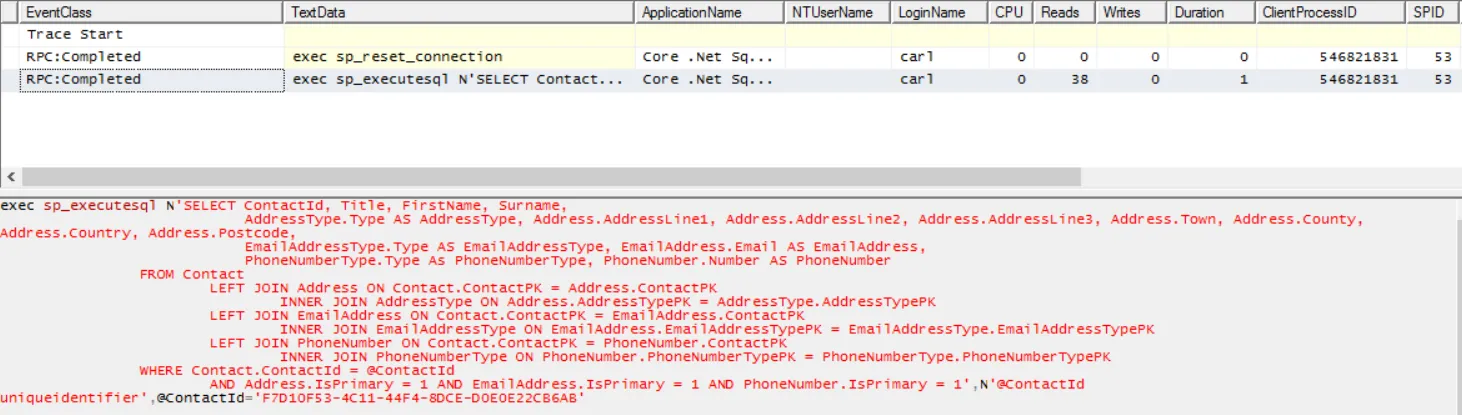
So, our ORM choice for the rest of this series on creating performant and scalable web APIs using ASP.NET core is Dapper. We’ll continue looking at data access in our next post - this time focusing on isolation levels and the impact on performance.
Comments
Saeid February 7, 2018
– By using ToList for Addresses = c.Addresses.Where(a => a.IsPrimary).ToList() and EmailAddresses and PhoneNumbers you are forcing it to cancel the deferred execution of the LINQ query. That’s why you have 4 calls per each materialization, one for SingleOrDefault and 3 for extra ToList()s.
– Judging an ORM based on the number of round trips to the DB is just wrong and unfair. What will happen if you change the name of Address.ContactPK in the 2nd example? Is it under the compiler’s supervision? Is it a completely a parametrized query? (no, it’s not). You have a new SqlConnection per each method. Do you know EF is able to reuse it per context’s life time? with more connections,you will have a slower application. How about the SQL injection attacks? Why .NET platform doesn’t suffer that much from these attacks like the PHP platform (which known for it)? Because even for an average Joe, all of the EF queries are parametric by default. How about having the first level cache by default (.Find() method) which causes less round trips to the DB? How do you compose a dynamic query here in a clean, safe and efficient way? You can chain EF queries/LINQ queries and at the end you will have just one single deferred SQL query, of course if you materialize it at the end of the chain and …
Michael Pendon July 6, 2018
Saeid, whatever you say on behalf of MS Entity Frameworks, both EF.Core and Entity Framework is not optimal when it comes to the Big Data RDBMS architecture. If you believe on this simplistic ORM approach of big ORMs like EF and NHibernate, then most likely, in the end of the game, you are just stoning yourself out of nowhere.
Micro-ORM is still the best ORM to go if you are working with the Big Data. Again, EF are not designed for enterprise applications. It was designed for lazy developers, and you know what I mean.
I am working with billion of rows, and believe me, EF and NHibernate is not performing well. I can even challenge the world out of it.
I liked EF but I do not like that it is not that flexible enough when it comes to fast-switch between light and massive ORM operations.
The only thing I can see good in EF is the, intellisense and integration at VS. Other than that, nothing else. And again, for me, it is for lazy developers.
P.S: I have talked the developers of EF during the MS Build last May 2018 and told them that their embedded ORM is not good and needs a rewrite in the foundation of Statement Building. But they said, they like challenger! 🙂
Ari Weinberger February 8, 2018
In the dapper SQL, you have LEFT JOINs to Address, EmailAddress and PhoneNumber. But in the WHERE clause you specify for each IsPrimary = 1.
That will result in 0 rows return if there is no record with IsPrimary record (essentially an INNER JOIN).
You should include IsPrimary = 1 in the LEFT JOIN clause rather than the WHERE clause.
Carl _February 8, 2018 _
Good point. Thanks Ari!
Gordon February 9, 2018
Leading with “Be careful with EF Core”, you are implying that ToList() materialising the query is some kind of ‘gotcha’… but I really can’t see how anyone would ever do that and expect any other result?!
Carl February 10, 2018
Thanks Gordon, fair point.
Zygimantas February 11, 2018
Where high performance is needed, use dapper .net, because orms like nh or ef prooved that cannot handle higher volumes of data with low latency.
Richard Tallent February 12, 2018
I’ve never actually used EF — when it came on the scene, I had a mature, stable, performant OR/M of my own design and saw no need to switch, and since I like SQL, I didn’t see any benefit in using LINQ to express my desired queries. I’ve used Dapper a few times and really like it.
That said, it should be mentioned that Dapper is read-only — creating, updating, and deleting isn’t in its vocabulary. If you need to write back to your database and want similar semantics, you can use the unofficial sidecar library (Dapper.SimpleCRUD).
Also, OR/M libraries are great for rapid development, but nothing beats the performance a well-designed, parameterized stored procedure paired with a hand-coded function to deserialize an object from IDataRecord.
Gary Woodfine February 13, 2018
The maintainability problem you create by embedding SQL within code is an absolute nightmare. There is DB code I can’t unit test. Basically divorced DB code from itself. What happens if I subsequently want to make a change to the DB schema , I literally have no idea what impact that would make with the running application ?
I understand and do concur with concerns over performance, but I wouldn’t agree that going back to design principles of 1999 is a good idea either. There is definitely a use case for Dapper, and I have used in projects, but I have always deferred from using it to inject SQL from the application.
As others have said, there are far better methods and means to develop you EF core queries than illustrated.
You have raised some interesting discussion points though. Good article!
Mick May 8, 2019
If i am not mistaking, ef also allows raw sql queries… So moving to dapper juust for this isn’t really a good call